По сколько в коде карты нельзя получить доступ к полям объекта, таких как защита юнита, классификация предмета, стоимость предметов и т.д., что создает некоторые не удобства, а иногда рушатся гениальные идеи. Один из самых простых способ добраться к нужной нам информации, это создание базы данных.
В этой статье я рассмотрю несколько примеров баз данных. Раскрою, пожалуй, важные аспекты и проблемы, с которыми можно столкнуться.
Что же такое база данных? База данных - это обычная таблица, в которой храниться нужная нам информация о ком или о чем либо.
Первые шаги
1. Планирование
При создании любой базы данных следует начинать именно с этого шага, иначе можно столкнуть с множеством проблем, решение которых может положить на нет всю работу проделанную ранее. Что же в этом шаге такого особенного? А то, что следует продумать, с какой целью нам нужна БД и что мы будем в ней хранить. Начнем по порядку. Допустим, я делаю карту, в которой я хочу добавить предметам новые данные: Коэффициент прочности (Насколько быстро ломается предмет), Минимальная прочность (Когда предмет становиться не пригодным для ремонта), Стоимость ремонта (Сколько стоит починка 1 ед. прочности). С помощью РО такое сделать достаточно сложно, а точнее вообще не возможно. После того, как мы продумали, что нам требуется от базы данных, мы можем перейти к непосредственному конструированию
2. Конструирование
На предыдущем шаге мы выяснили, как должна выглядеть наша БД. В этом шаге мы рассмотрим простую (табличную) базу данных. Её создание не составит нам труда. Табличная БД состоит из 2 главных элементов - это поле и запись. Поле БД - элемент, который определяет, что мы будем хранить в нем, а так же тип хранимых данных. Запись - непосредственно данные. Давайте теперь разберемся, какие поля нам требуется создать:
- Коэффициент прочности
- Минимальная прочность
- Стоимость ремонта
Теперь надо понять, какие значения нужно хранить в них. С этим ничего сложного, в нашем примере видно, что оптимальным вариантом будет целое (integer) значение. Получается, что нам нужно будет создать таблицу с 3 полями, в которой будут храниться значения типа целое (integer)
3. Реализация
Теперь мы знаем, какие должны быть поля у нашей базы данных. Перейдем к непосредственной реализации БД в редакторе. Для этого открываем редактор триггеров. Затем открываем окно редактора переменных. И начинаем создавать нужные поля, для этого нажимаем создать переменную, выбираем нужный тип, даем нужное имя переменной и не забываем ставить галочку Массив (Array). И так нужно сделать для каждого поля БД. Теперь поясню, почему именно так. Массив - это линейная таблица, то есть таблица размером 1х8192. Поэтому создавая еще переменные, получаем уже прямоугольную таблицу. В нашем случае получается таблица, размером 3x8192. В своем примере я прозвал переменные, следующим образом:
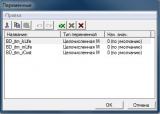
BD_itm_kLife Поле №1
BD_itm_mLife Поле №2
BD_itm_rCost поле №3
Советую, вам именовать переменные по такому же принципу, а именно: BD_<имя БД>_<имя поля>. Я считаю, что так лучше ориентироваться в списке переменных.
После того как создали все эти переменные, нужно инициализировать БД. Это делается очень просто. Создаем новый триггер, например BD_itm_InitTrig. В событии указываем инициализация карты. В действиях заполняем поля. Например, у меня есть предмет "Кинжал не прочности". Он имеет следующий код в игре 'I001' (RawCode). Если вы не знаете, как его узнать, то зайдите в Редактор объектов (РО) и нажмите ^D (Ctrl+D), и вы увидите список кодов. По сколько массивы в игре ограничены размером в 8192, индекс может лежать только в пределах от 0 до 8191, а наш код 'I001' = 73*256^3+1 = 1224736769. Как видите, он превышает размер массива, чтобы напрямую его использовать в качестве индекса (ID) записи в БД. Поэтому произведем небольшую манипуляцию с этим числом. Мы просто вычтем основание равкода предмета, а оно равно 'I000'. Получим 'I001' - 'I000' = 1.
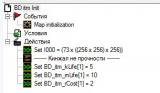
Вот и все наша БД инициализирована. Теперь поговорим, как её использовать. Допустим, у нас есть триггер, который срабатывает, когда оружие ломается. В нем нужный предмет уже записан в переменную broke_item. Нам нужно уменьшить его прочность. Но как нам подобраться к коэффициенту прочности? Просто! Для этого мы возьмём равкод нужного нам предмета с помощью функции GetItemTypeID, вычтем значение 'I000' из него, после полученное значение мы используем в качестве ID в БД.
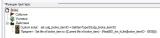
Поскольку в GUI нет возможности напрямую вводить равкод, да и вообще такое число там ввести просто не реально, то я предлагаю такой выход: создадим еще одну переменную типа целое (integer) с именем I000 и зададим значение 1224736768 = 73 * 256^3. Теперь при вычитании можно использовать переменную.
Полное погружение в реализацию
4. Реализация с помощью Jass
Приступая к этой части, я предполагаю, что читатель уже ознакомлен с Jass и имеет хотя бы минимальное представление о vJass
В предыдущей части статьи я рассказал, как создать БД в GUI. Довольно таки рутинная работа. Да и подбираться к данным не очень удобно. Поэтому предлагаю рассмотреть еще один вариант создания БД на jass, а точнее на vJass, т.к. он обладает некоторыми полезными свойствами. Реализовывать будем точно такую же БД. Для начала создадим новый триггер, сконвертируем его в текст и очистим содержимое полностью. Триггер я назвал "ItemEx Data". Для удобства создадим библиотеку, так можно будет скрыть информацию, которая не рекомендуется для просмотра. В библиотеке нам понадобиться функция для инициализации, пока оставим её пустой. На данном этапе у вас должно быть, что то вроде этого:
library ItemExDataLib initializer InitLib
//Реализация БД для предметов
//Функция инициализации библиотеки
private function InitLib takes nothing returns nothing
endfunction
endlibrary
Теперь нам нужно создать саму БД. В принципе процесс ничем не отличается от GUI'шного, только, наверное, даже быстрее. Описывать ячейки базы очень просто с помощью структур. Напомню, что нам нужны 3 поля (Коэффициент прочности, Минимальная прочность, Стоимость ремонта) типа Integer (Целое). Ну что создадим нашу структуру поля БД:
struct ITEMEXDATA
integer kLife = 0
integer mLife = 0
integer rCost = 0
endstruct
Как видите, ничего сложного. Теперь осталось создать саму таблицу данных. Для этого в блоке globals/endglobals создаем новый массив, например "ItemExData". Дальше я бы советовал добавить функцию для автоматического внесения новой записи в БД. Например, такую:
public function AddNewRecord takes integer ItemID, integer kLife, integer mLife, integer rCost returns ITEMEXDATA
set ItemExData[ItemID - 'I000'] = ITEMEXDATA.create()
set ItemExData[ItemID - 'I000'].kLife = kLife
set ItemExData[ItemID - 'I000'].mLife = mLife
set ItemExData[ItemDB - 'I000'].rCost = rCost
return ItemExData[ItemDB - 'I000']
endfunction
Осталось только добавить соли по вкусу, и наша БД будет готово. А вся соль в заполнении данных. Для этого вернемся к нашей функции инициализации. В ней нужно будет вызывать функцию добавления новой записи в БД, с нужными значениями. Давай те внесем данные о нашем "Кинжале не прочности". Это делается таким кодом:
call AddNewRecord('I001', 5, 10, 2)
Полностью моя библиотека теперь выглядит вот так:
» code
А теперь как нам все это получить непосредственно в коде карты. Допустим нам надо получить стоимость затрат на ремонт предмета, находящегося в переменной itm. Стоимость ремонта занесем в переменную repairCost, а возможность починки занесем в переменную isCanRepair
...
set itmLife = GetItemLife(itm)
set itmId = GetItemTypeId(itm) - 'I000' //Id предмета в БД
set isCanRepair = itmLife >= ItemExData[itmId].mLife
if isCanRepair then
//Вычесляем стоимость починки предмета
set repairCost = (GetItemMaxLife(itm) - itmLife)*ItemExData[itmId].rCost
//Дальнейшие действия
...
else
//Вывод сообщения, что предмет починить не возможно
...
endif
...
Как видите ничего сложного. На этом данная часть статьи заканчивается
5. Подводные камни и их решение
Теперь рассмотрим некоторые корыстные случаи, которые нас могут поджидать. Увы, не все предметы имеют хороший диапазон равкодов и при вычитании базового равкода, id все равно выходит за пределы размерности массивов. Но предметы это еще полбеды, а если нам нужно записывать данные для юнита? У них базовый равкод зависит от расы, поэтому вычитание базового равкода нам ничего не даст. Так что нам придется изменить структуру нашей базы данных. Давай те создадим еще одну, но теперь только для юнитов, где будет храниться его стоимость, для примера я выбрал следующие ресурсы: железо, нефть и камень. Для хранения данных пригодится тип integer (целое). Создадим новую библиотеку по такому же принципу, как и в прошлой части статьи. Далее создаем структуру (я её назвал UNITEXDATA), от предыдущего пункта в принципе ничего не отличается, кроме парочки моментов. Первым делом нам нужно добавить два новых приватных поля типа integer (целое) с именем id и unitRawCode. Это нам понадобиться для поиска нужной нам информации. Так же потребуется еще одно приватное статическое поле, таково же типа - integer, в котором будет храниться кол-во занятых ячеек в БД. В итоге это у меня выглядит так:
struct UNITEXDATA
private static integer count = 0 //Занятые ячейки
//=====
private integer id //Положение записи в БД
private integer unitRawCode //raw code нашего юнита
integer MetalCost = 0 //Стоимость
integer OilCost = 0
integer StoneCost = 0
endstruct
Теперь осталось создать нужные методы (для создания, нахождения и удаления новой записи в БД). Теперь расскажу о получении id для записи. Будем брать последнюю доступную ячейку. Для этого нам и понадобилась информация о кол-ве занятых ячеек. А при удалении будем очищать текущую ячейку, и переносить данные с последней ячейки в только-что освободившуюся. Теперь непосредственно код:
static method Create takes integer unitRawCode, integer MetalCost, integer OilCost, integer StoneCost returns UNITEXDATA
local UNITEXDATA this = .create()
set .id = .count //Записываем в последнюю ячейку
set .count = .count + 1 //увеличиваем кол-во занятых ячеек
set UnitExData [.id] = this //UnitExData - наша база данных (UNITEXDATA array UnitExData) объявленная в globals текущей библиотеки
//Записываем данные
set .unitRawCode = unitRawCode
set .MetalCost = MetalCost
set .OilCost = OilCost
set .StoneCost = StoneCost
return this
endmethod
method Destroy takes nothing returns nothing
set .count = .count - 1 //Уменьшаем кол-во занятых ячеек
set UnitExData[.id] = UnitExData[.count] //Переносим последнюю ячейку на место текущей
set UnitExData[.id].id = .id //Обновляем информацию о положении ячейки
call .destroy()
endmethod
Теперь осталось написать поиск нужной нам записи. Вы можете использовать любой другой способ поиска записи, даже с предварительной сортировкой, ну а я воспользуюсь обычным перебором.
static method Get takes integer UnitRawCode returns UNITEXDATA
local integer i = .count - 1
loop
exitwhen i < 0
if UnitExData[i].unitRawCode == UnitRawCode then
return UnitExData[i]
endif
set i = i - 1
endloop
return 0
endmethod
В принципе ничего сложного. Для заполнения данных используем метод Create. Это делается таким образом:
call UNITEXDATA.Create('hfoo',50,0,0)
//А для получения информации используем такой код:
local integer mCost = UNITEXDATA.Get('hfoo').MetalCost
Кто не разобрался с кусочками кода вот полная библиотека:
» code
Теперь рассмотрим небольшую функцию для проверки на возможность строительства здания\юнита
function CanBuild takes integer unitId returns boolean
local UNITEXDATA record = 0
set record = UNITEXDATA.Get(buildId)
if record == 0 then
return true
endif
return record.MetalCost <= currentMetal and record.OilCost <= currentOil and record.StoneCost <= currentStone
endfunction
Как видите, мы используем дополнительную локальную переменную, в которой хранится указатель на нужную нам запись в БД. Таким образом, мы ищем запись всего один раз, вместо четырех. Четвертая идет на проверку. Желательно её делать самостоятельно, тогда можно избежать не предсказуемости выполнения кода. Если же вам достаточно все один раз получить значение в записи и вам далеко начхать на проверку, то можно воспользоваться и такой конструкцией:
UNITEXDATA.Get('hfoo').MetalCost
Но запомните, такая конструкция не приемлема.
6. Возможные доработки и улучшения
В предыдущем пункте мы создали базу данных для юнитов. Для того, чтобы использовать запись несколько раз нам приходилось создавать новую переменную, в которую записывали найденное значение. Сейчас я покажу один небольшой трюк, который упростит работу с записями. Для этого мы добавим новую статическую приватную запись в нашу структуру этого же типа, что и сама запись. Назовем её lastFounded и назначим начальное значение на 0. Для начала изменим метод Get в нашей структуре, так, чтобы при повторном поиске такой же записи он не искал, а сразу выдал нужный указатель. Это делается так
method Get takes integer UnitRawCode returns UNITEXDATA
local integer i = .count - 1
if .lastFounded != 0 then //Если мы недавно искали этот равкод, то вернем найденную ранее запись
if UnitRawCode == .lastFounded.unitRawCode then
return .lastFounded
endif
endif
//В прошлый раз искали другое, поэтому ищем по новой
loop
exitwhen i < 0
if UnitExData[i].unitRawCode == UnitRawCode then
set .lastFounded = UnitExData[i] //Запоминаем найденную запись
return UnitExData[i]
endif
set i = i - 1
endloop
//Сбрасывать предыдущую запись нет смысла, так как она может пригодиться
return 0
endmethod
Этот код не сильно отличается от оригинального, лишь добавилось пару условий на проверку. Теперь можно спокойно писать так:
function CanBuild takes integer unitId returns boolean
if UNITEXDATA.Get(unitId) == 0 then
return false
endif
return UNITEXDATA.Get(unitId).MetalCost <= currentMetal and <...>
endfunction
Теперь остается только одно неудобство. Запрос происходит через длинную цепочку методов. Но и это можно легко исправить. Для этого в vJass есть очень полезная функция перегрузки операторов. Мы воспользуемся оператором []. Для этого требуется создать статичный метод оператор. Он выглядит так
static method operator [] takes integer id returns UNITEXDATA
<...>
endmethod
Данный оператор может принимать только число и возвращать что угодно. Теперь осталось написать внутренность этого оператора. А она очень простая, нужно вызвать метод Get с переданным в оператор значением. В итоге получаем следующий метод для перегрузки оператора
static method operator [] takes integer id returns UNITEXDATA
return .Get(id)
endmethod
А теперь еще один вариант функции CanBuild
function CanBuild takes integer unitId returns boolean
if UNITEXDATA[unitId] == 0 then
return false
endif
return UNITEXDATA[unitid].MetalCost <= currentMetal and <...>
endfunction
Как вы уже могли заметить мы пришли к такому же использованию нашей БД, как и в пункте 4. Для тех, кто не полностью разобрался, прикладываю код всей структуры, библиотека в целом не изменилась, поэтому не вижу смысла её включать.
» code
Теперь я бы хотел рассказать о более быстрых способах поиска. Поскольку простой перебор при большом объеме данных может обойтись дорого, если обращение к БД происходит достаточно часто. Если же у вас не горит повысить скорость доступа к записи в БД, то эту часть статьи можно пропустить. А теперь собственно о способах поиска. Есть много разных алгоритмов поиска в массиве. Я показал один из самых простых, это полный перебор. Довольно таки долгий, но простой метод. Так же существует алгоритм поиска с помощью дерева. Про него я вам и хочу рассказать. Суть его в том, чтобы разделить область поиска на 2 части. Проверить в одной. Если его нет в той области, значит он в другой. Вторую часть делят еще на 2 части. И так до тех пор пока не найдут нужный объект. Если же делать поиск в частях таким же образом, хоть скорость и увеличится, но не на очень много. Так как мы ищем числовую информацию, то мы можем быстро производить поиск простым сравнением. Для этого потребуется отсортировать нашу область поиска. Например, по возрастанию. Дальше простыми вопросами найти маленький участок и пройтись по нему перебором. Для начала рассмотрим алгоритм на небольшом примере. Допустим, у нас есть ряд чисел, и нам надо найти число 8
9 5 2 3 4 1 6 8 7 //Сортируем по возрастанию
1 2 3 4 5 6 7 8 9 //Выбираем средний элемент и задаем вопрос: 8 < центрального числа, если да, то вырезаем левую часть и повторяем действие, если число больше, то вырезаем правую часть, ну а если равны, то центральный элемент искомый
5 6 7 8 9 //Повторяем предыдущий шаг.
8 9 //Поскольку длина этого кусочка меньше рекомендованного < 3, то переберем
В результате мы нашли наше число уже на 4 шаге. Если бы мы перебирали массив, потребовалось бы намного больше попыток. Осталось только реализовать этот алгоритм поиска.
Начнем с сортировки массива. Для этого в нашей структуре создадим пару новых статических методов. Один для сортировки, другой для перестановки элементов массива местами, назовем их Sort и Reloc соответственно.
private static method Reloc takes integer i, integer j returns nothing
local UNITEXDATA loc = UnitExData[i]
set UnitExData[i] = UnitExData[j]
set UnitExData[j] = loc
//=====
set UnitExData[i].id = i
set UnitExData[j].id = j
endmethod
//Пузырьковая сортировка
//Легко запомнить, легко применить, адекватно работает до 400-500 элементов
//Для больших советую qSort + тот же пузырек при длине кусочка < 256
static method Sort takes nothing returns nothing
local integer i = 0
local integer j = 0
loop
exitwhen i < .count
set j = i
loop
exitwhen j < .count
if (UnitExData[i].unitRawCode < UnitExData[j].unitRawCode) then
call .Reloc(i,j)
endif
set j = j + 1
endloop
set i = i + 1
endloop
endmethod
Теперь мы можем отсортировать нашу БД по рав коду юнитов, что сможет ускорить процесс поиска. Для этого надо переписать наш старый метод Get
method Get takes integer UnitRawCode returns UNITEXDATA
local integer i = .count - 1
local integer startIndex
local integer endIndex
if .lastFounded != 0 then
if UnitRawCode == .lastFounded.unitRawCode then
return .lastFounded
endif
endif
call .Sort()
set i = .count / 2
set startIndex = 0
set endIndex = .count - 1
loop
endloop i < 4
set i = i / 2
if (UnitRawCode < UnitExData[startIndex+i].unitRawCode) then
set endIndex = startIndex + i
elseif (UnitRawCode > UnitExData[startIndex+i].unitRawCode
set startIndex = endIndex - i
else
set .lastFounded = UnitExData[startIndex+i]
return UnitExData[i]
endif
endloop
set i = startIndex
loop
exitwhen i <= endIndex
if UnitRawCode == UnitExData[i].unitRawCode then
set .lastFounded = UnitExData[i]
return UnitExData[i]
endif
set i = i + 1
endloop
set .lastFounded = 0
return 0
endmethod
Метод написан, поиск работает чуть быстрее. Но давайте рассмотрим такой случай, когда мы изменяли БД только в самом начале, а потом постоянно обращались к какой-нибудь записи. Исходя из выше приведенного листинга, сортировка будет выполняться каждый раз, когда мы пытаемся обратиться к данным, но к чему нам такие затраты? Правильно не к чему, поэтому я предлагаю такой выход. Обзавестись новой статической приватной переменной типа boolean с названием isUpdated. По умолчанию это поле должно иметь значение false. Данный флаг отвечает за состояние массива нашей БД. При всяком изменении массива, связанном с положением ячеек, надо устанавливать этот флаг на значение true. Такими действиями являются создание и удаление записей из базы данных. Для этого надо дописать в методах Create и Destroy такую строчку:
set .isUpdated = true
Теперь заменим эту строчку из метода Get
call .Sort()
на эту
if .isUpdated then
call .Sort
endif
Так же в метод сортировки надо сбросить флаг изменения. В итоге у вас должна получиться такая структура
|